





本文目录导读:
随着大数据时代的到来,数据处理和分析变得越来越重要,Hive作为一种在Hadoop上构建的数据仓库基础架构,广泛应用于大数据处理领域,本文将介绍如何在12月实时将增量数据接入Hive,探讨如何优化数据存取流程,提高数据处理效率,并辅以实际案例分析,帮助您更好地理解和应用这一技术。
理解数据增量与Hive的重要性
在大数据时代,数据的实时处理和分析至关重要,增量数据是指在一个特定时间段内新产生的数据,对于企业和组织来说,这些数据蕴含着丰富的价值,而Hive作为一种可扩展的数据处理平台,能够高效地存储、查询和分析这些数据,将12月的实时增量数据接入Hive,有助于企业快速获取有价值的信息,提高决策效率。
数据接入Hive的挑战与解决方案
在将实时增量数据接入Hive的过程中,可能会遇到一些挑战,如数据格式多样性、数据质量、实时性要求等,针对这些挑战,我们可以采取以下措施:
1、数据格式多样性:由于增量数据可能来自不同的源,存在格式多样性问题,我们可以通过数据清洗和转换工具,将数据统一转换为Hive可识别的格式。
2、数据质量:保证数据质量是数据接入Hive的前提,我们需要对数据进行校验和清洗,确保数据的准确性和完整性。
3、实时性要求:为了满足实时性要求,我们可以采用流处理技术和消息队列,将数据实时传输到Hive中。
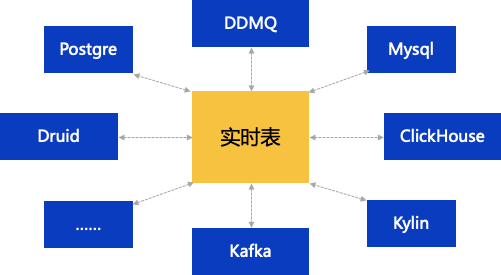
三、实践案例:12月实时增量数据接入Hive的应用
以下是某电商企业成功将12月实时增量数据接入Hive的案例:
该电商企业每天产生大量的用户行为数据,为了更准确地分析用户行为,提高营销效果,该企业决定将实时增量数据接入Hive。
具体实施过程如下:
1、数据收集:通过部署在网站服务器上的数据收集器,实时收集用户行为数据。
2、数据处理:将收集到的数据进行清洗、转换和校验,确保数据质量和格式统一。
3、数据接入Hive:通过Hadoop集群和Hive接口,将处理后的数据实时写入Hive表中。
4、数据分析:利用Hive的SQL查询功能,对实时数据进行查询和分析,获取有价值的信息。
通过这一实践,该电商企业实现了数据的实时处理和分析,提高了营销活动的精准度和效果。
技术要点与最佳实践
在将12月实时增量数据接入Hive的过程中,需要注意以下几个技术要点和最佳实践:
1、选择合适的数据格式和存储方式,以提高数据查询效率。
2、保证数据质量和准确性,避免错误数据的干扰。
3、采用流处理技术和消息队列,满足实时性要求。
4、合理利用Hive的查询优化技术,提高数据处理效率。
通过将12月实时增量数据接入Hive,企业可以更加高效地处理和分析数据,获取有价值的信息,本文介绍了相关的实践指南、技术挑战和解决方案,以及实际案例分析,希望能对读者有所帮助,随着技术的不断发展,我们相信未来会有更多的创新方法应用于数据处理领域。
转载请注明来自江西海派厨业有限公司,本文标题:《实践指南,高效接入Hive存储与处理12月实时增量数据》





 京公网安备11000000000001号
京公网安备11000000000001号 蜀ICP备2022005971号-1
蜀ICP备2022005971号-1
还没有评论,来说两句吧...